 , M. Saygin Seyfioglu , Fatemeh Ghezloo - Equal Contribution
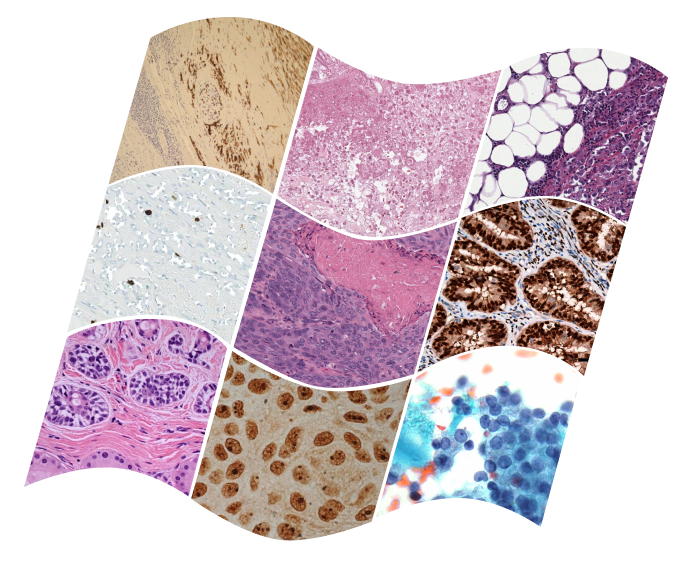
, M. Saygin Seyfioglu , Fatemeh Ghezloo - Equal Contribution Recent accelerations in multi-modal applications have been made possible with the plethora of image and text data available online. However, the scarcity of similar data in the medical field, specifically in histopathology, has halted similar progress. To enable similar representation learning for histopathology, we turn to YouTube, an untapped resource of videos, offering 1,087 hours of valuable educational histopathology videos from expert clinicians. From YouTube, we curate Quilt: a large-scale vision-language dataset consisting of 768,826 image and text pairs. Quilt was automatically curated using a mixture of models, including large language models), handcrafted algorithms, human knowledge databases, and automatic speech recognition. In comparison, the most comprehensive datasets curated for histopathology amass only around 200K samples. We combine Quilt with datasets, from other sources, including Twitter, research papers, and the internet in general, to create an even larger dataset: Quilt-1M, with 1M paired image-text samples, marking it as the largest vision-language histopathology dataset to date. We demonstrate the value of Quilt-1M by fine-tuning a pre-trained CLIP model. Our model outperforms state-of-the-art models on both zero-shot and linear probing tasks for classifying new pathology images across 13 diverse patch-level datasets of 8 different sub-pathologies and cross-modal retrieval tasks.
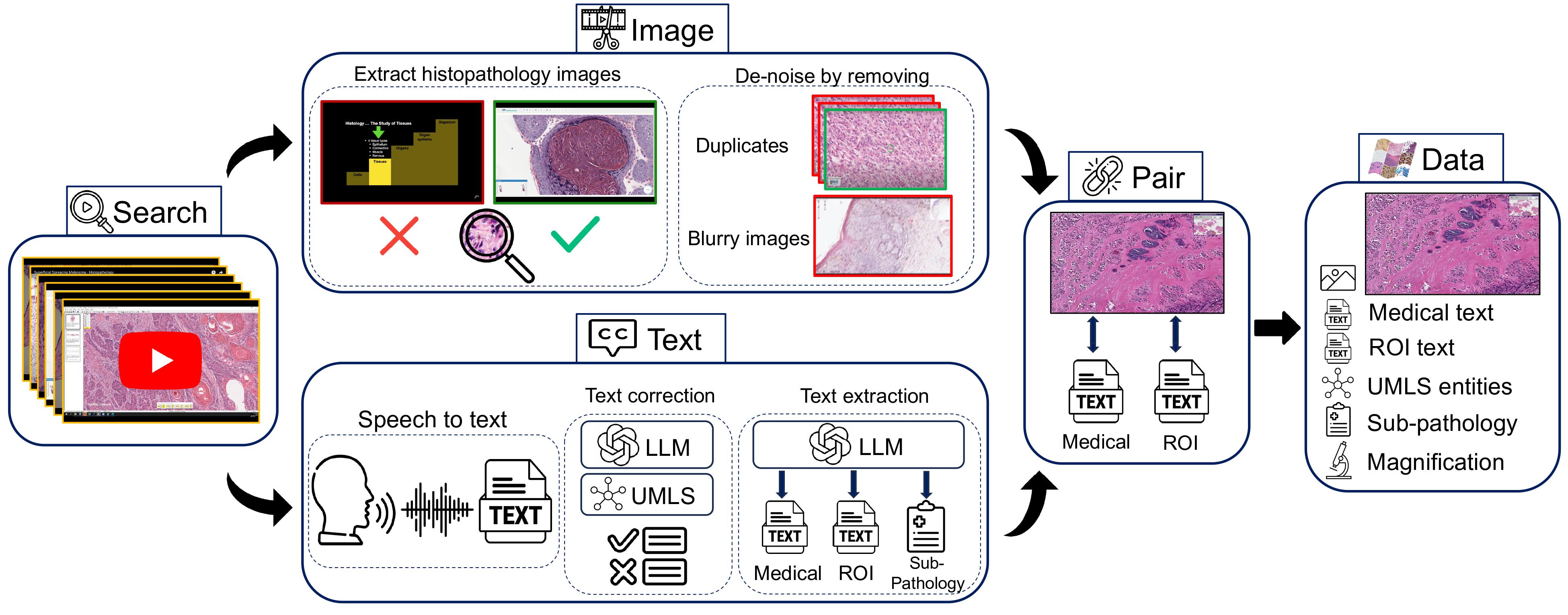
To address the need for a large-scale vision-language dataset in histopathology, we introduce Quilt: containing 419,780 images aligned with 768,826 text pairs. We draw on the insight that publicly available educational YouTube histopathology content represents an untapped potential. We curate Quilt using 1,087 hours of valuable educational histopathology videos from expert pathologists on YouTube. To extract aligned image and text pairs from the videos, we utilize a mixture of models: large language models, handcrafted algorithms, human knowledge databases, and automatic speech recognition. Quilt does not overlap with any current open-access histopathology data sources. This allows us to merge our dataset with other open-source datasets available. Therefore, to create an even larger and more diverse dataset, we combine Quilt with data from other sources, such as Twitter, research papers, and the Internet, resulting in Quilt-1M. The larger Quilt-1M contains one million image-text pairs, making it the largest public vision-language histopathology dataset to date.
We collected Quilt, from 4504 narrative videos spanning over 1087 hours with over 438K unique images with 768K associated text pairs.
The mean length of the text captions is 22.76 words, and 8.68 words for ROI text, with an average of 1.74 medical sentences per image (max=5.33, min=1.0).
Our dataset spans a total of 1.469M UMLS entities from those mentioned in the text (with 28.5K unique). The images span varying microscopic magnification scales (0-10x, 10-20x, 20-40x), obtaining (280K, 75K, 107K) images from each scale respectively.
One of our narrative videos can be seen below.
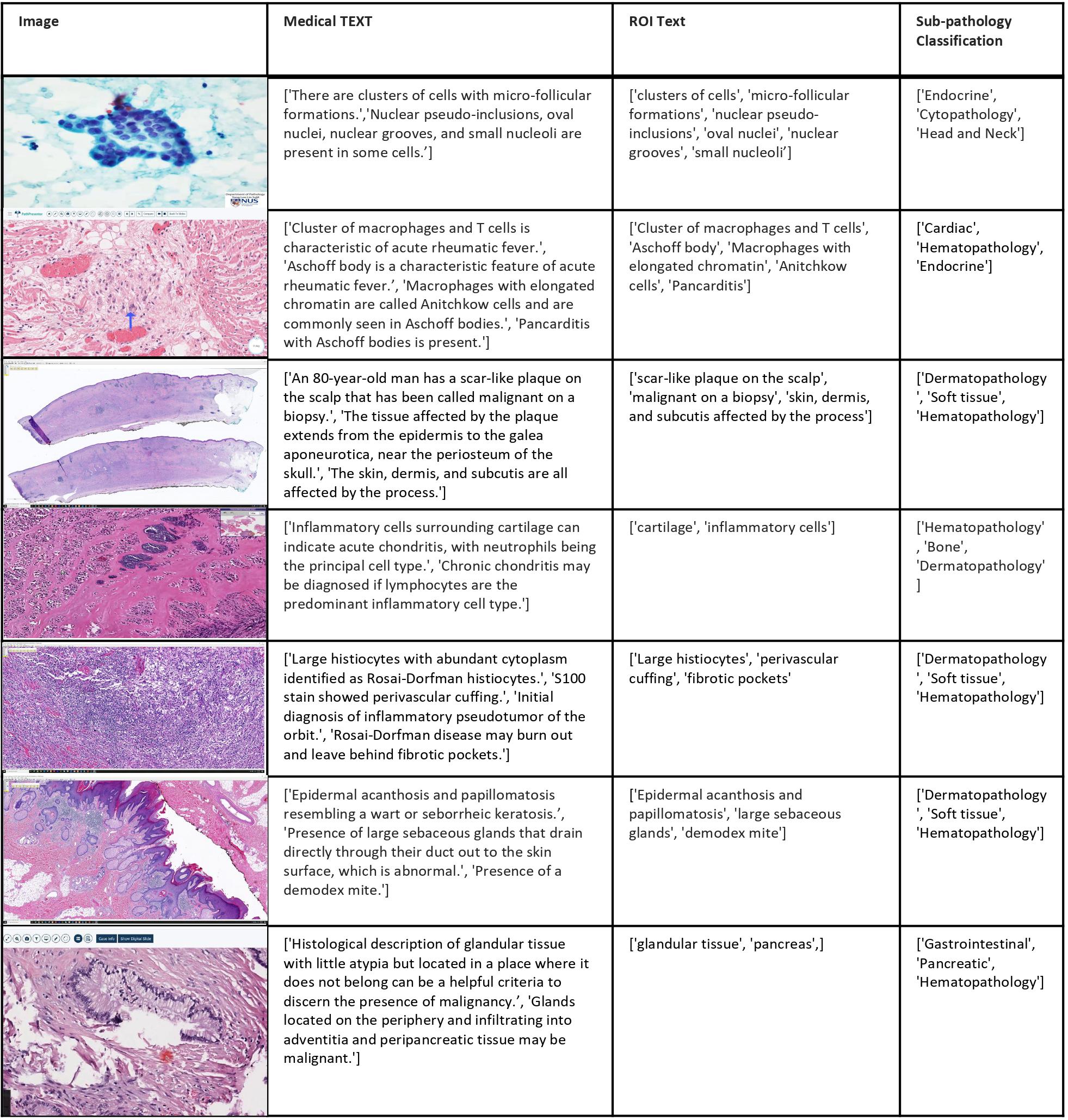
Following are the collection of sample images from our dataset, accompanied by corresponding medical
text, ROI text, and the top three sub-pathology classifications:
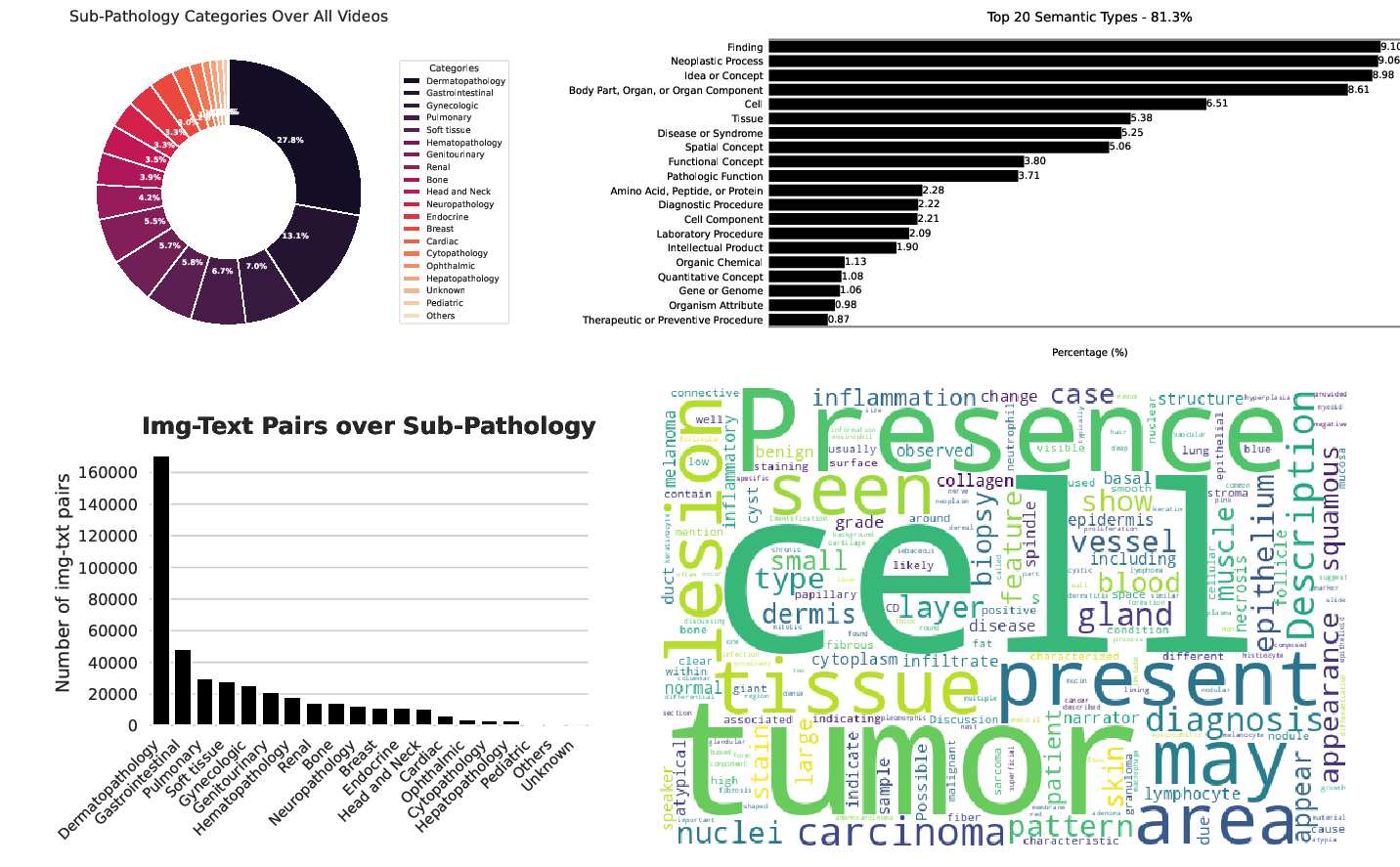
Following figures illustrate the distribution of data across 18 sub-pathology types, offering a comprehensive analysis of the dataset's text distribution.
We use the Contrastive Language-Image Pre-training (CLIP) objective to pretrain QuiltNet
using Quilt-1M. QuiltNet, outperforms out-of-domain CLIP baseline and state-of-the-art histopathology
models across 12 zero-shot tasks, covering 8 different sub-pathologies (accuracy percentage provided).
Results using linear probing: We assess the few-shot and full-shot performance of our model by conducting linear probing with 1%, 10%, and 100% of the training data, sampled with three different seeds. Remarkably, our model, utilizing the ViT-B/32 architecture with GPT/77, outperforms its counterparts, PLIP, BiomedCLIP, and CLIP, in most datasets.
Results using cross-modal retrieval:In our study, we evaluate cross-modal retrieval efficacy by examining both zero-shot text-to-image and image-to-text retrieval capabilities. Our experiments are conducted on two datasets: our holdout dataset from Quilt-1M and the ARCH dataset. In terms of cross-modal capabilities our QuiltNet performs better in most of the cases compared to it's counterparts.
Links to our model demonstrations can be found here: QuiltNet-B-32 QuiltNet-B-16 QuiltNet-B-16-PMB

Wisdom O. Ikezogwo

M. Saygin Seyfioglu

Fatemeh Ghezloo

Dylan Geva

Fatwir S. Mohammed

Pavan K. Anand

Ranjay Krishna

Linda Shapiro
- Equal First Author Contribution@article{ikezogwo2023quilt,
title={Quilt-1M: One Million Image-Text Pairs for Histopathology},
author={Ikezogwo, Wisdom Oluchi and Seyfioglu, Mehmet Saygin and Ghezloo, Fatemeh and Geva, Dylan Stefan Chan and Mohammed, Fatwir Sheikh
and Anand, Pavan Kumar and Krishna, Ranjay and Shapiro, Linda},
journal={arXiv preprint arXiv:2306.11207},
year={2023}
}
Any questions about Quilt, or want to get in touch? Contact Wisdom at wisdomik at cs.washington.edu.
